Pour les data scientists #5
Convertir la voix en texte, ou les techniques de speech-to-text
Cette newsletter vous est envoyée par l’agence Predict Boost et les formations ML Academy. Pour tout sujet concernant vos données, vous pouvez prendre rendez vous via notre site internet.
On s’intéresse cette semaine à la retranscription de voix sous forme écrite, communément appelé dans la littérature le speech-to-text.
Les applications sont multiples, et le challenge technique conséquent : on va devoir effectuer un travail sur des données audios, du NLP, des méthodes de deep learning, le tout avec des contraintes de production - streaming et capacités de calcul et storage.
Les applications
Le speech-to-text offre de nombreuses possibilités. On peut notamment analyser le texte retranscrit avec des techniques de NLP - comme l’analyse de sentiments ou autre classification spécifique.
Voici quelques applications en vrac :
Retranscription pour les malentendants, comme la startup ava
Sous-titrage automatique, intégré dans la plupart des logiciels d’édition vidéo, de Youtube à veed.io en passant par Adobe Premiere
Gong.io qui a levé plus de $300m fait de l’analyse d’interactions avec des prospects en sales
Analyse et optimisation d’interactions du support client, comme la startup indienne observe.ai
Une vraie utilité donc, comment l’implémenter?
L’implémentation
Première Approche
La première piste, récupérer une API existante. GCP, AWS, Azure implémentent des points d’entrée pour effectuer du speech to text en temps réel et asynchrone. On peut aussi passer par une plateforme API spécialisée comme rev.ai.
A l’instar de tout projet software, on essaie d’évoluer de manière agile, et faire fonctionner un prototype end-to-end même à 80% des capacités. C’est encore plus le cas si on doit gérer des problématiques supplémentaires - streaming, ou autre sujet d’architecture, et valider la viabilité du projet.
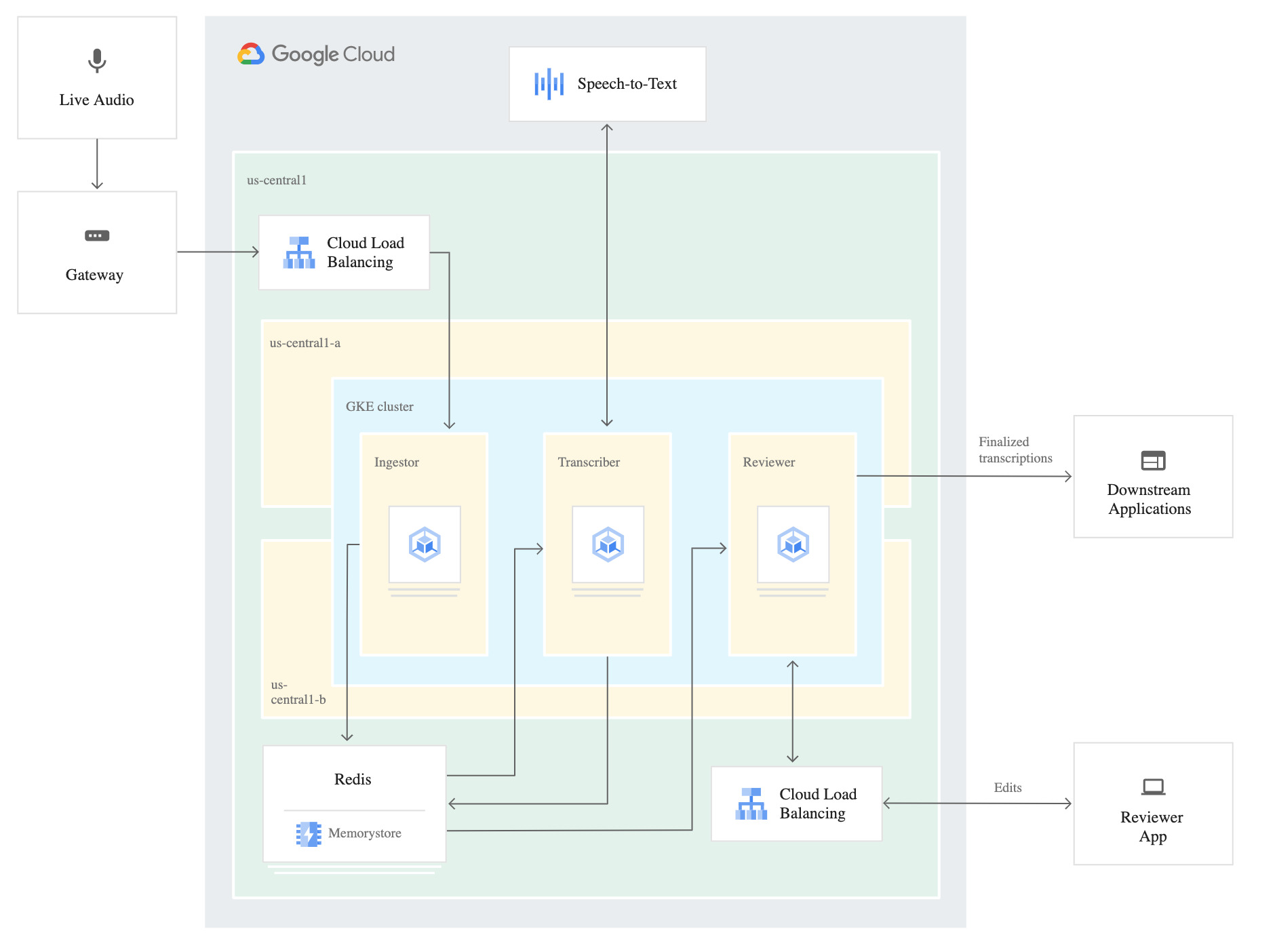
Approfondissement
On peut maintenant réfléchir à implémenter son propre modèle - si l’API n’est pas viable à l’échelle pour des contraintes de coût, de manque performance, ou pas assez spécifique à notre besoin.
L’entraînement est à la fois coûteux et nécessite un jeu de donnée d’entraînement (des sons + retranscription associées) potentiellement laborieux à récupérer. Du travail en perspective.
Plus de détails ci-dessous sur les concepts à solliciter dans le cas ou vous voulez vous lancer dans votre propre implémentation.
Les concepts
Le speech-to-text mobilise de nombreuse notions de machine learning. Encore une fois, le travail avec des couches convolutionelles est plébiscité. On part en effet d’un spectre audio, donc un signal brut qu’il va falloir interpréter. Intuitivement, le spectre audio possède des corrélations locales à l’instar des images, qui justifient l’usage de CNN
Un bon point de départ est de récupérer le wav2vec qui est un modèle non-supervisé pré-entraîné permettant de récupérer une représentation vectorielle de l’audio, pour ainsi s’en servir comme features sur votre modèle spécialisé spécifique.
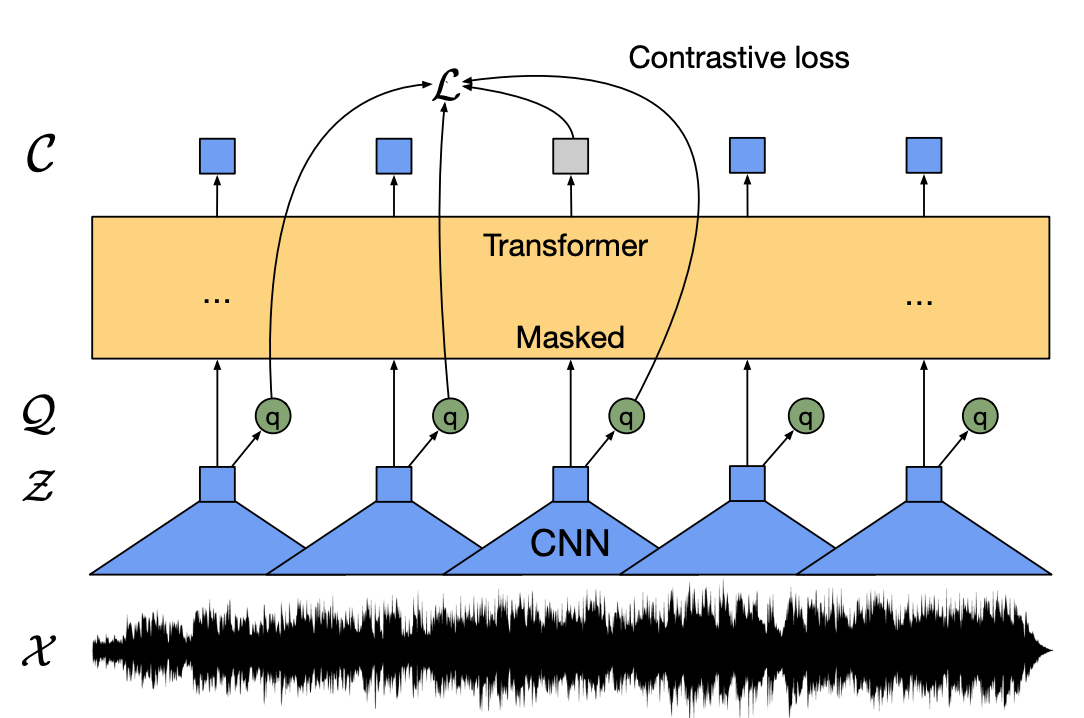
Wav2vec est implémenté à l’origine dans la librairie Facebook fairseq. On peut aussi tester d’autres lib qui l’implémentent comme vectorhub.
Autres Pistes
On peut aussi travailler sur le spectre audio directement pour détecter différentes intonations qui peuvent être intéressantes, par exemple qui traduisent des émotions.
Combiner la vidéo quand c’est possible, avec des techniques de vision supplémentaires permet aussi parfois d'améliorer la retranscription.
Enfin, retranscrire le texte est généralement seulement la première étape avant de passer à l'analyse de texte - on pourra donc regarder du côté des techniques NLP mais ce sera pour une prochaine newsletter 😇
Une question d'entretien
Comment éviter le sur-apprentissage pour un modèle de random forest ?
Le sur-apprentissage arrive souvent lorsque la complexité du modèle est trop grande par rapport au nombre d’observations contenues dans le set d'apprentissage. Il convient donc en général d'essayer de diminuer la complexité de notre modèle, ou de le contraindre.
Par utilisation de la validation croisée, comme tout autre modèle.
Comme pour les arbres de décision, par utilisation du pruning: en deux mots, réduire la taille des arbres, pour réduire leur complexité
En pratique, en contrôlant la taille de la forêt, et en agissant sur le nombre minimal d’observations par feuille ainsi que la profondeur maximale.
On veut idéalement utiliser des forêts moins profondes mais contenant plus d'arbres.
C’est tout pour cette semaine. Si vous avez des questions ou remarques, n’hésitez pas à répondre directement à cet email.